Purpose
There are tens of thousands of Near Earth Asteroids (NEAs) on orbit paths close to Earth, with more being discovered daily (CNEOS, 2025a). Some of these become classified as Potentially Hazardous Asteroids (PHAs), as they become large enough to potentially cause a problem. As more and more NEAs are discovered every day, it would be helpful to develop a machine learning classification system that would be able to classify NEAs to determine which could be hazardous. Classification of asteroids requires time-consuming analysis of a variety of features. An autonomous model would allow space agencies to dedicate more resources to observation of the detected PHAs and developing mitigation strategies. Accurate and expedient classification of asteroids is crucial to determining potential risks to planetary health. This project develops a model to classify NEAs based on physical and orbital characteristics to determine which could be hazardous to Earth. This project cleans and pre-processes the dataset, selects relevant features, and trains a model using machine learning to classify asteroids as hazardous or non-hazardous.

Strategy
We utilized a Histogram-based Gradient Boosting Classifier (HGBC), as they handle structured tabular data well, manage non-linear relationships, and allow weighting for class imbalance, all of which are a benefit with this dataset. We placed an emphasis on the recall metric, as in this case missing hazardous asteroids is more problematic than falsely classifying one as hazardous. We used a variety of feature engineering techniques, and random search to find optimized hyperparameters. To further optimize the results, we switched to balanced class weights, which automatically upweights the rarer positive class. We also switched hyperparameter tuning to optimize for the f-beta (f2) metric, which has a higher focus on recall, and implemented random over sampling (ROS), which duplicates instances of the positive class so they appear more often in the dataset. Finally, we used a stratified train-test split, which ensured there's a similar ratio of positive to negative classes in each split.
Results
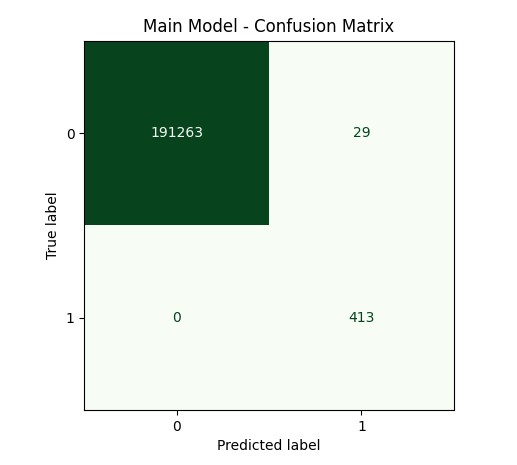
We were able to classify the posed hazard of asteroids with the following results:
- Accuracy: 99.98%.
- Recall: 100%
- Precision: 93.44%
- F1 Score: 96.61%
These were excellent results. To our knowledge, this outperforms all previously published baselines on this Kaggle dataset as of the time of writing. The confusion matrix for our final model is shown.
Github: Repo
Final report: Report PDF
Data Set: Kaggle Dataset